Qt Corner: cells.py
Copyright 2019 Brian Davis - CC-BY-NC-SA
Part of the QtCorner series.
https://gitlab.com/intrepidhero/qt-corner/-/tree/master/cells
cells.py is a very basic spreadsheet application that showcases a number of interesting programming topics. I avoided doing anything too interesting with the interface, choosing instead to focus on three things: Subclassing QAbstractTableModel and extending it, linking the resulting model with a QTableView, and writing a spreadsheet resolver that evaluated python expressions entered into the spreadsheet.
Qt's powerful widgets really shine here in QTableView and QAbstractTableModel. A pretty minimal amount of code gets you a powerful tool. In the past I've used QTableWidget and populated it manually but in this case I wanted to try out Qt's model-view classes and add a pythonic dictionary like interface to the table model.
Extending QAbstractTableModel
When using Qt for Python, aka PySide2 to interface with QtWidgets, subclassing existing Qt classes is a normal method to add features or combine widgets. And it's extremely easy. I declare a class PyTableModel that subclasses QAbstractTableModel and in its __init__ function call QAbstractTableModel. With most Qt classes that is all that is required but since this is a abstract base class (ABC) there is a defined minimal interface that must be implemented. The downside to working python here is that none of the tooling will tell you about this interface like say the C++ compiler would. You have to read the documentation, carefully.
The important parts are data(index, role), setData(index, value, role), flags(index), headerData(section, orientation, role), rowCount(parent), and columnCount(parent).
I started by adding a dictionary to the class to hold the data. For large spreadsheets this could become a problem since all the data is in memory at once. But I initialized the dictionary to 100 rows and 676 columns (A-ZZ) and did not add provisions for making it larger. For the time being it's a fixed matrix of cells. I originally set out to use my dictionary as a sparsely populated matrix but found that QTableView would not render cells that didn't have a value in the model. Probably I need to extend the model to return a default set of values of for unpopulated cells.
Notice I said, "set" of values. I was confused by this notion of roles that show up in the method signatures. The Qt documentation was not particularly revealing on what the roles are or how they are used. I eventually stumbled on some example code that showed testing for role == Qt.DisplayRole. And searching the docs for that I see the QtCore.Qt.ItemDataRole is an enumeration containing things like ToolTipRole and BackgroundRole so I guess the view can ask the model for different kinds of item related to each item and the role is how it differentiates. For now I'm just going to focus on DisplayRole because that is all I care about. I first discovered that the role was important when I filled my model with random bits of data and observed that each cell had bizarre and unpredictable formatting. To debug that I placed a print statement in PyTableModel.data that printed the index and role. That showed that data() was being called many times on each index with many different roles. I was returning the display value every time and that didn't seem right.
The next gotcha was to set the correct flags. I was used to setting flags on QTableWidget to enable editing but with model-view you must set the flags on an item by item basis.
headerData checks role (for DisplayRole) and orientation (horizontal or vertical headers). I'm still not exactly sure what section means as the documentation just says "QtCore.int". But it didn't seem to be important at this stage.
rowCount and columnCount both get a value called parent, which is a QModelIndex, presumably pointing to another item in the model. This would make sense for a tree model but I don't see myself using it in a table model.
To add a dictionary like interface I implemented __getitem__, __setitem__, __len__, and __iter__ that for the moment simply expose the corresponding methods of the member dictionary. Since QAbstractTableModel uses column and row integers to refer items (these are members of QModelIndex passed to data and setData) I used a tuple (column, row) as the keys into my dictionary.
Linking to a QTableView
Linking the model to a view is quite straightforward. Create the model, create the view and call view.setModel(model). I stacked two QTableViews on a QWidget and used menu actions to switch back and forth between them. One view is linked to a model containing formulas (python expressions) and the other is populated with values.
Solving the Spreadsheet
As I thought about how to evaluate the spreadsheet I realized I had a problem. I could take all the formulas, concatenate them into a string of source code and run them through exec. But I wouldn't know the proper order for executing so that all dependencies were resolved. In fact I knew that sometimes the user might enter cyclical dependencies (of the form a = b, b = a) and I needed a way to detect those and alert the user to the mistake. First I thought I could look through all the expressions and pick out the ones with no dependencies (constants). Those should go at the top. Then I could make a graph of the remaining expressions where each node pointed to the things it depended on. I didn't realize at first that this would be a graph. I wanted to call it a tree and I was at a loss for how to compute the order. I researched and eventually saw a note where someone said this general dependency ordering problem is solve by performing a topographical sort on an acyclic graph. That was my "Aha!" moment. An acyclic graph is a graph of parent child relationships (ie expressions with dependencies) that do NOT have circular references. Searching further on those magical terms lead me to this explanation which is extremely helpful and even includes implementations in Java, C++ and Python. But the default implementation is a recursive one and I tend to avoid recursive algorithms when writing Python for a couple reasons. Mainly: Python has a recursive function limit and I don't like to worry about whether my data will lead to hitting the limit. Secondly, Python function calls can be expensive, so iterative algorithms are generally preferred. Fortunately the same geeksforgeeks article lists a reference to Kahn's algorithm, which is similarly performant, iterative, and contains a delightfully well documented python implementation. Back to the keyboard Batman!
In my code for cells.py you'll see a PyTableResolver class. The three functions it contains are completely independent of state and so should probably have been three separate functions with no class at all. But in the moment as I was writing it I didn't know if I would need any shared or persistant state in the resolver code so I started with a class and then left it because it organized the sorting related functions neatly. No doubt this class could be refactored into something more elegant.
The basics of Kahn's algorithm are:
-
Count the dependencies of each expression, saving the ones that have zero, and making a look up table where the keys are cells and the values are lists of cells that depend on the key.
-
Loop through all the expressions that have zero dependencies adding each one to the list of sorted expressions. For each cell that depends on this cell decrement the number of dependencies it has, if it now has zero add it to the list of "to be processed".
-
Count the number of cells in the sorted list. If there is a circular dependency the resulting list not be the same length as the unsorted list.
A couple interesting problems cropped up here. Remember that my models use (column, row) tuples to index cells. Those are cumbersome to input as the user so I allowed the user to enter excel-like references (A1, B1, etc) so I had to write functions that convert between the two forms. Second I had to figure out how to recognize the cell references in the expression. I could have written a regular expression, but I was worried about false positives given how generic [A-Z]+[0-9]+ would be. Given these expressions are supposed to all be valid python I wondered if I could leverage the python parser at all. Searching turned up tokenize. Using that to parse the expressions while counting dependencies allows me to find the cell references and possibly support other valid python variables in the future.
Finally with the sorted list complete I compile and execute the python code. The results come back in the locals dictionary that I pass into exec. It is read and copied to the values model.
Results
Screenshots aren't very interesting.
Formulas
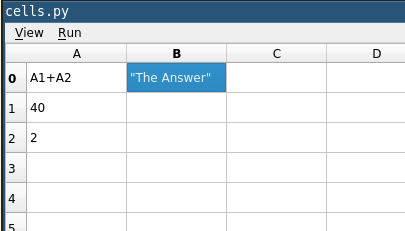
Values
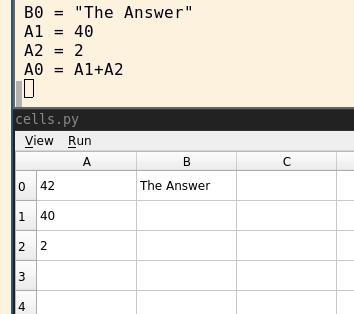
Notice how the terminal (that I launched the script from) shows the python source of the spreadsheet. Errors pop up there too.
All told this was a fun and interesting project that taught me some new things. Success!
Further explorations could involve fleshing out the UI, handling python evaluation errors better, support for adding/removing rows/columns, cell formatting, or replacing the backend with sqlite.